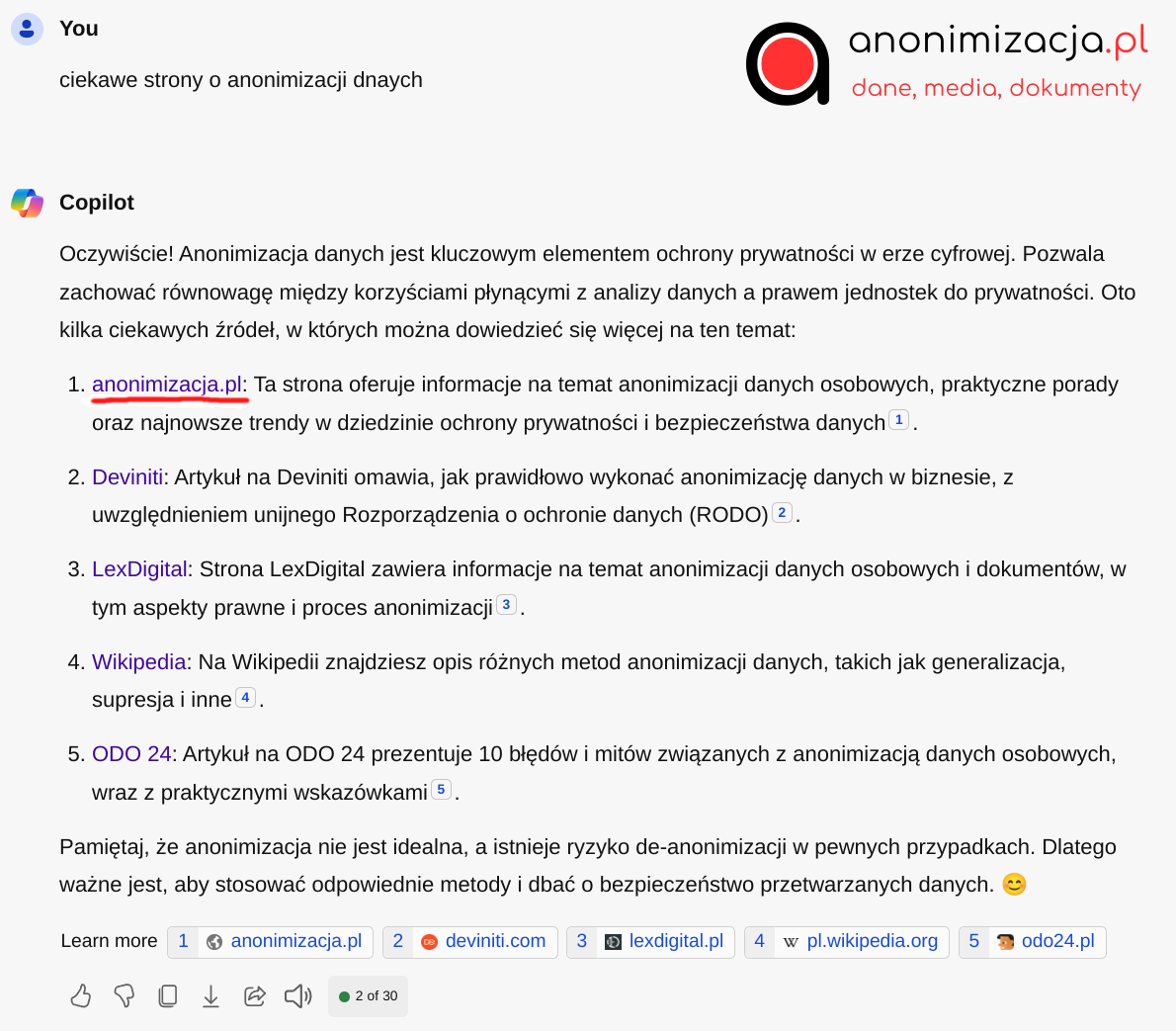
Obserwujemy rosnące napięcie między potrzebą dostępu do danych dla rozwoju AI a ochroną praw własności intelektualnej i prywatności.
Sytuacja ta może prowadzić do nowych rozwiązań w zakresie anonimizacji danych i bardziej etycznego podejścia do ich wykorzystania w AI. Dziś można wyróżnić kilka kluczowych trendów i problemów związanych z AI i dostępnością danych:
Spis treści
Ograniczanie dostępu do danych treningowych:
- Wiele stron internetowych zmieniło swoje warunki użytkowania, zabraniając crawlerom zbierania danych lub wykorzystywania ich treści do trenowania systemów AI.
- Wzrosła liczba stron stosujących pliki robots.txt do ograniczania dostępu crawlerów.
- Szczególnie widoczne jest to w przypadku serwisów informacyjnych, gdzie ograniczenia wzrosły z 3% do 45% w ciągu roku.
Zróżnicowane podejście do różnych firm:
- Strony internetowe często blokują crawlery konkretnych firm, np. OpenAI, podczas gdy pozwalają na dostęp crawlerom innych firm, jak Google czy Meta.
Problemy prawne i licencyjne:
- Pojawiły się pozwy sądowe przeciwko firmom AI, oskarżające je o nielegalne wykorzystywanie danych do treningu.
- Niektóre firmy, jak OpenAI, zaczęły płacić wydawcom za dostęp do ich treści.
- Platformy takie jak Reddit czy Stack Overflow zaczęły pobierać opłaty za dostęp do swoich API.
Wpływ na rozwój AI:
- Ograniczenie dostępu do danych może spowolnić rozwój systemów AI, szczególnie w sektorze akademickim i non-profit.
- Może to prowadzić do nierówności w dostępie do wysokiej jakości danych treningowych.
Anonimizacja i ochrona prywatności:
- Chociaż tekst nie odnosi się bezpośrednio do anonimizacji, można wywnioskować, że rosnące ograniczenia w dostępie do danych mogą być częściowo motywowane chęcią ochrony prywatności użytkowników.
- Firmy i platformy mogą dążyć do większej kontroli nad tym, jak ich dane są wykorzystywane, co może prowadzić do lepszych praktyk w zakresie anonimizacji i ochrony danych osobowych.
Przyszłość dostępu do danych:
- Istnieje potrzeba wypracowania nowych modeli biznesowych i prawnych, które pozwolą na równoważenie interesów firm AI, wydawców treści i użytkowników.
- Konieczne może być stworzenie jasnych regulacji prawnych dotyczących wykorzystania publicznie dostępnych danych do trenowania AI.